Upon registration, you will receive an invitation to join the Discord server of the challenge.
Description
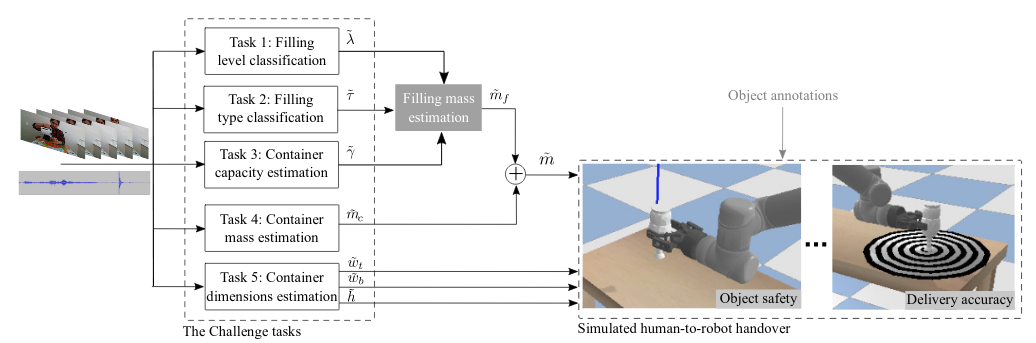
The CORSMAL challenge focuses on the estimation of the capacity, dimensions, and mass of containers, the type, mass, and filling (percentage of the container with content), and the overall mass of the container and filling. The specific containers and fillings are unknown to the robot: the only prior is a set of object categories (drinking glasses, cups, food boxes) and a set of filling types (water, pasta, rice).
Containers vary in shape and size, and may be empty or filled with an unknown content at 50% or 90% of its capacity. The tasks are as follows:
Task 1 (T1)Filling level classification. The goal is to classify the filling level as empty, half full, or full (i.e. 90%) for each configuration
Task 2 (T2)Filling type classification. The goal is to classify the type of filling, if any, as one of these classes: 0 (no content), 1 (pasta), 2 (rice), 3 (water), for each configuration.
Task 3 (T3)Container capacity estimation. The goal is to estimate the capacity of the container for each configuration.
Task 4 (T4)Container mass estimation. The goal is to estimate the mass of the (empty) container for each configuration.
Task 5 (T5)Container dimensions estimation. The goal is to estimate the width at the top and at the bottom, and height of the container for each configuration.
The weight of the object is the sum of the mass of the (empty) container and the mass of the (unknown) filling, multiplied by the gravitational earth acceleration, g=9.81 m/s-2. We expect methods to estimate the capacity, dimensions, and mass of the container and to determine the type and amount of filling to estimate the mass of the filling. For each configuration, we then compute the filling mass using the estimations of filling level from T1, filling type from T2, and container capacity from T3, and using the prior density of each filling type per container. The density of pasta and rice is computed from the annotation of the filling mass, capacity of the container, and filling level for each container. Density of the water is 1 g/mL. The formula selects the annotated density for a container based on the estimated filling type.
The challenge uses CORSMAL Containers Manipulation as reference dataset. See the webpage for more details and download the data.
- View 1: view from the fixed camera on the left side of the manipulator
- View 2: view from the fixed camera on the right side of the manipulator
- View 3: view from the fixed camera mounted on the manipulator (robot)
- View 4: view from the moving camera worn by the demonstrator (human)
- A: audio modality
- RGB: colour data
- D: depth data
- IR: infrared data from narrow-baseline stereo camera
- ZCR: Zero-crossing rate
- MFCC: Mel-frequency cepstrum coefficients
- ZCR: Zero-crossing rate
- A5F: Audio 5 features (MFCC, chromogram, mel-scaled spectrogram, spectral contrast, tonal centroid)
- kNN: k-Nearest Neighbour classifier
- SVM: Support Vector Machine classifier
- RF: Random Forest classifier
- PCA: Principal component analysis
SWAPPING! Score of container mass: s7 -> s4. Scores for container dimensions: (s4, s5, s6) -> (s5, s6, s7).
OFFSET!
Scores for object safety (s9) and delivery accuracy (10) do not account for testing configurations where failures were introduced by the simulator. Both scores have been also increased equally for all teams by an offset to account for inaccuracies introduced by the simulator. The value of the offset for each test set (public, private, combined) is determined as the residual between 100 and the score computed with annotated physical properties (ground-truth) provided as input to the simulator.
SWAPPING! Score of container mass: s7 -> s4. Scores for container dimensions: (s4, s5, s6) -> (s5, s6, s7).
OFFSET!
Scores for object safety (s9) and delivery accuracy (10) do not account for testing configurations where failures were introduced by the simulator. Both scores have been also increased equally for all teams by an offset to account for inaccuracies introduced by the simulator. The value of the offset for each test set (public, private, combined) is determined as the residual between 100 and the score computed with annotated physical properties (ground-truth) provided as input to the simulator.
SWAPPING! Score of container mass: s7 -> s4. Scores for container dimensions: (s4, s5, s6) -> (s5, s6, s7).
OFFSET!
Scores for object safety (s9) and delivery accuracy (10) do not account for testing configurations where failures were introduced by the simulator. Both scores have been also increased equally for all teams by an offset to account for inaccuracies introduced by the simulator. The value of the offset for each test set (public, private, combined) is determined as the residual between 100 and the score computed with annotated physical properties (ground-truth) provided as input to the simulator.
Training of an efficient Convolutional Neural Network, e.g. Mobilenet-v2 with Coordinate Attention, to compute deep features from both the sliding windows of the audio signals converted in log-Mel features and the synchronized RGB frames of the video from the fixed, frontal view. Deep audio features are re-used from the fine-tuning of the Mobilenet-v2 for filling type classification, and concatenated with the deep visual features. Concatenated features are fed into an LSTM unit prior to the final prediction with fully connected layers.
Task 2:
Training of an efficient Convolutional Neural Network, e.g. Mobilenet-v2 with coordinate attention, to compute deep audio features from the sliding windows of the audio signals converted in log-Mel features. Deep audio features are fed into an LSTM unit prior to the final prediction via majority voting.
Task 3:
Fine-tuning of an efficient Convolutional Neural Network, e.g. Mobilenet-v2 with coordinate attention, using i) data augmentations, and ii) variance-consistency evaluation. The model is pre-trained on Task 5 (container dimensions estimation) and takes as input RGB-D image crops of the containers extracted with a YOLO-v5 detector from the fixed, frontal view. Data augmentation: image crops and corresponding capacity labels are randomly and proportionally resized by a scaling factor (drawn by a truncated uniform distribution and keeping the distance value fixed) to account for the intrinsic 2D-3D geometric relationship and the limited training data (labels). The variance-consistency evaluation aims at selecting the model that achieves the highest accuracy and the lowest total variance across the samples from the validation set, based on the observation that predictions of the capacity for the same container should be consistent.
Task 4:
Fine-tuning of an efficient Convolutional Neural Network, e.g. Mobilenet-v2 with coordinate attention, using i) data augmentations, and ii) variance-consistency evaluation. The model is pre-trained on Task 5 (container dimensions estimation) and takes as input RGB-D image crops of the containers extracted with a YOLO-v5 detector from the fixed, frontal view.
Task 5:
Training of an efficient Convolutional Neural Network, e.g. Mobilenet-v2 with coordinate attention, using i) data augmentations, and ii) variance-consistency evaluation. The model is pre-trained on Task 5 (container dimensions estimation) and takes as input RGB-D image crops of the containers extracted with a YOLO-v5 detector from the fixed, frontal view.
Keywords:
Transfer learning, Mobilenet-v2, Coordinate Attention, LSTM, Data augmentation, Variance-consistency evaluation
(Jointly with Task 2) A model composed of a shared 2-layer Convolutional Neural Network (depthwise convolutional layer
and a pointwise convolutional layer), a shared Transformer (3 encoder blocks, each with a 4-head self-attention layer, 2 Layer-Norm layers, 2 Fully Connected layers) , and 2 task-specific Multi-Layer Perceptron heads (2 fully connected layers). The model takes as input audio signals pre-processed and transformed into mel-spectrograms in logarithmic scale, discarding portions of the signal at the beginning and ending with a randomly amount (e.g., 0-40% and 60-100%, respectively).
Task 2:
See Task 1.
Task 3:
The method builts on LoDE, a multi-view iterative fitting approach that estimates the 3D shape (point cloud) of rotationally symmetric objects as a hypothetical cylinder constraint to the binary object masks in two fixed, wide baseline camera views. The method modifies how the radii are reduced across iterations to account for the hand occlusions and smooth the 3D model. For the binary object masks, the method defines a formula to determine the frame and pair of views among the three fixed views (frontal, and 2 sides) where the container is most visible to overcome partial occlusions, low detection confidences, and containers detected too close at the image borders. To estimate the capacity, the volume of the 3D shape is approximated to the Riemman sum of the partial volumes (slicing method) as a canonical frustum.
Task 4:
Regression approach of the container mass with a custom CNN that takes as input a resized image-crop of the container extracted from the best selected frame (see Task 3) and the object mask of the left side, fixed view. The architecture of the CNN has four 3x3 convolutional layers with a padding of size 1 and 3 fully connected (FC) layers. Each convolutional layer is followed by the ReLU activation function, batch normalization, and 2x2 max-pooling layers, and each FC layer by the ReLU activation function and batch normalization layer. The output of the second FC is concatenated with the vector containing the container dimensions (height, width at the bottom, width at the top). To overcome the problem of chipped object masks due to the hand occlusions, mask restoration is addressed by exploiting the symmetrical property of the containers and hence pixel replacement is perfomed after determining the symmetric axis on the image plane.
Task 5:
See Task 3. The container dimensions are estimated as a by-product of the estimated 3D shape.
Keywords:
Convolutional Neural Network, Transformers, Multi-Layer Percpetron, Log-Mel Spectrograms, Best frame selection, LoDE, slicing method, mass regression, object mask restoration.
Regression of the (empty) container mass with a shallow Convolutional Neural Network that takes RGB image crops from the fixed, frontal view. Patches of the container are detected in a video by using Mask R-CNN pretrained on COCO and selecting relevant categories (e.g., cup, book, wine glass, bottle).
A set of patches is then automatically selected based on the nearest distance to the view by exploiting the depth data within the segmentation mask of the container in the corresponding RGB frame. Predicted masses by the deep model for the selected patches are averaged to obtain the final mass estimation.
Keywords:
Convolutional Neural Networks, Object detection, Mass estimation
Audio + RGB from all views. GRU(VGGish) + GRU(R(2+1)d [RGB-only]) for each view, and RandomForest(classical audio features)
Task 2:
Audio. GRU(VGGish) and and RandomForest
Task 3:
RGB + IR + Depth (left-side view). LoDE on detector's predictions; if no object was detected, use of the training set's average
Summary:
We sum up logits from all four views obtained from GRU on top of R(2+1)d features to form one prediction for each event, which are, then, averaged with the GRU output on top of VGGish features, and RandomForest predictions on top of 30+ classical audio features (eg mfccs, chromagram, energy, spread). LoDE with Mask R-CNN for object detection (glass, bottle, or book for boxes), in frame 1 and 20 of the videos (view 1, RGB-D-IR) to estimate container capacity. Average of the training set is used if no detection.
Audio. From the prediction model for Task2, intermediate features are extracted and pass through LSTM models.
Task 2:
Audio. Raw audio waveform converted into a log-Mel spectrogram that is cropped into a fixed-size and provided as input to convolutional neural network model with a VGG backbone.
Task 3:
RGB + Depth from view 1: fixed camera on the left side of the manipulator (robot). Mask-RCNN detects the target object (silhouette) and a point cloud is obtained from a selected frame in the video. The volume of the container is then computed by approximating the object shape as a cuboid from the point cloud.
Audio and RGB from all views. Integrate the audio feature learning and the knowledge of container categories via the object detection pre-trained model.
Task 2:
Audio and RGB from all views. Integrate the audio feature learning and the knowledge of container categories via the object detection pre-trained model.
Task 3:
RGB from all views. Sample from the shape distribution based on the prior of container categories
Summary:
The solution is divided into three folds to help the agent shape a rich understanding of the pouring procedure. First, the agent obtains the prior of container categories (cup, glass, box) through the object detection framework. Second, audio features are integrated with the prior to make the agent learn a multi-modal feature space. Finally, the agent infers the distribution of both the container capacity and fluid properties.
Depth from view 3: the fixed camera mounted on the manipulator (robot)
Summary:
Extraction of 40 normalized MFCC features in a window size of 20 ms at 22 kHz, with a maximum length of 30 s, and zero-padding to preserve the same duration across audio data. Filling type classification with a neural network consisting of 2 convolutional layers and 1 linear layer. Regression of the container capacity by extracting a region of interest (ROI) around the object localised in the depth data (view 3) and providing the ROI and its size to a neural network (4 convolutional-batchnorm followed by 3 linear layers). The size of the ROI is concatenated to the feature between the 2nd and 3rd linear layer. Only detections/ROIs up to 700 mm far from the camera, while processing the video backwards, are considered (prior knowledge that the person will extend the arm towards the robot). The closest contour is selected, if multiple detections in a frame.
Sound-based classification of filling type and level: After suppressing the noise in each audio signal via spectral gating, the absolute value of the Short-Time Fourier Transform (STFT) is extracted as input feature for a classifier based on a 5-layer fully connected neural network, trained with Adam optimizer and dropout on the last layer to reduce overfitting.
Paper:
N/A
Code:
N/A
Team name:
Organisers
Team members:
Santiago Donaher
Alessio Xompero
Andrea Cavallaro
Task 1:
Audio
Task 2:
Audio
Task 3:
N/A
Summary:
Sound-based model that first identifies the action performed by a person with a container and then determines the amount and type of content using an action-specific classifier. The models consists of three independent CNN classifiers and combines content types and levels into a set of seven feasible classes. Task 1 and Task 2 are jointly performed by the model.
The CORSMAL challenge evaluates and ranks the teams by assigning a 100 point-based score that accounts for a set of objective performance scores and an assessment of the submitted source code for reproducibility. The integrity of the submitted results is ensured by having a public test set with no annotations available to the teams and a private test set with both the data and the annotations not available to the teams. For the public test set, teams run their models on their own and submit their results in a constrained amount of time. For the private test set, organisers will install, run and evaluate the teams' models.
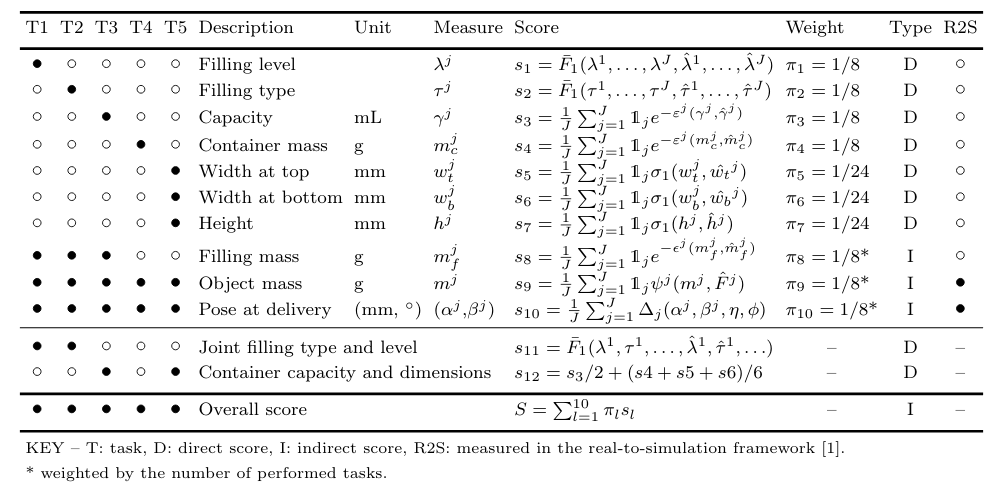
To provide a sufficient granularity into the behaviour of the various components of the pipeline, we use 10 performance scores for the challenge tasks across public and private sets. The first 7 scores quantify the accuracy of the estimations for the 5 main tasks. The last 3 scores are an indirect evaluation of the impact of the estimations on the quality of human-to-robot handover and delivery of the container by the robot. Performance scores will be also computed individually for the public CCM test set, the private CCM test set, and their combination. The scores cover filling level, filling type, container capacity, container width at the top, width at the bottom, and height, container mass, filling mass, object mass (container + filling), and the delivery of the container upright and at a pre-defined target location.
For a measure a, its corresponding ground-truth value is â. The scores are normalised, and the overall score is in the interval [0,100]. F1 is the weighted average F1-score. Filling amount and type are sets of classes (no unit).
See the document for technical details on the performance measures.
The challenge also evaluates and ranks the teams on additional groups of tasks:
Joint filling type and level classification. Estimations and annotations of both filling type and filling level are combined in 7 feasible classes and the weighted average F1-score is recomputed based on these classes.
Container capacity and dimensions estimations We combine the scores for the two tasks (s3, s4, s5, s6) with a weighted average, i.e. 1/2 for s3 and 1/6 for s4, s5, s6.
Filling mass estimation. The score for filling mass (s8) is computed from the estimations of filling type, filling level, and container capacity, and weighed by the number of tasks performed by the teams (i.e., 0.33 for one task, 0.66 for two tasks, 1 for the three tasks). The score is not a linear combination of the scores outputted for filling level classification (Task 1), filling type classification (Task 2), and container capacity estimation (Task 3), it takes into consideration the formula for computing the filling mass (see the document for technical details) based on the estimations of each task for each configuration. This means that a method with lower Task 1, Task 2 and Task 3 scores can obtain a higher score for filling mass compared to other methods because the performance on each configuration is more accurate in general. Note that estimations from the random case are used for the tasks that are not addressed by the teams to compute the filling mass.
The scores for the three groups of tasks are computed individually for the public CCM test set and the private CCM test set, as well as their combination.
Rules
Teams
Teams, which can include individuals from one or more institutions, must pre-register using the online form, or via email, and nominate a contact person.
Individuals can be team up with other individuals by the organisers, if they wish.
All teams will be referred to using codenames (e.g., provided team names during the registration) in rank order.
The organisers are not allowed to participate in the competition.
Solution design and development
Teams are free to choose the platform where to develop their own solution, subject to the requirements that the source code is reproducible, easy-to-install, and easy-to-run by the organisers during the evaluation stage.
Organisers encourage teams to adopt GitHub as hosting platform for software development, distributed version control using Git, and source code management. Organisers offer to set up private repositories (one for each team) where the members of a team are added as contributors to then develop their solution. It is totally up to each team if they want to choose this solution.
Inferences must be generated automatically by a model that uses as input(s) any of the provided modality or their combination (e.g., images, audio or audio-visual fusion). Non-automatic manipulation of the testing data (e.g., manual selection of frames) is not allowed.
The use of prior 3D object models is not allowed (e.g., the reconstruced shapes of the containers in 3D provided for the simulator).
The only prior knowledge available to the models is the high-level set of categories of the containers (cup, drinking glass, food box), the set of filling types (water, rice, and pasta) and the set of filling levels (empty, half-full, and full).
The use of additional training data is allowed (but the provided test set cannot be used for training).
Organisers encourage the teams to officially release any new annotations on the CCM dataset for reproducibility by the community.
Models must perform the estimations for each testing audio-visual recording only using data from that recording, and the training set; not from other recordings. Learning (e.g., model fine tuning) across testing recordings is not allowed.
Teams will not be allowed to use infrared data.
Online solutions - i.e., solutions that can be run on a continuous stream as for the case of human-to-robot handover - are preferred. To encourage this type of solution, organisers will refer to the CORSMAL real-to-simulation framework that allows the participants to observe models would perform for a human-to-robot handover.
The source code should be properly commented and easy to run. Organisers will provide guidelines for the software requirements to encourage the teams in using standard virtual environments and libraries (e.g., Anaconda).
Teams will submit the source code of their solution to the organisers who will install and run the solutions and generate the estimations for each configuration on the private CCM test set. The organisers will require to input an absolute path to the testing set to perform the evaluation. Therefore, teams should prepare the source code in such a way that data path is provided as input argument. Organisers recommend teams to have a single README file with a brief description; employed hardware, programming language, and libraries; installation instructions; demo test; running instructions on the testing set; external links to pre-trained models to download, if any; and licence.
Note that organisers will run the submitted software with the following specifications:
Hardware
- CentOS Linux release 7.7.1908 (server machine)
- Kernel: 3.10.0-1062.el7.x86_64
- GPU: (4) GeForce GTX 1080 Ti
- GPU RAM: 48 GB
- CPU: (2) Xeon(R) Silver 4112 @ 2.60GHz
- RAM: 64 GB
- Cores: 24 Libraries
- Anaconda 3 (conda 4.7.12)
- CUDA 7-10.2
- Miniconda 4.7.12
Estimations outputted for each configuration of the public and private test sets by the teams' algorithms must follow the format of the template provided by the organisers.
Columns related to tasks not addressed by the teams should be filled with -1 values. Method failures or configurations not addressed should also be filled with -1 values. Filling mass column can be left empty (all -1 values) as the estimations will be computed automatically by the evalution toolkit using the estimations from filling level, filling type, and container capacity columns. The three columns about object safety and delivery accuracy will be estimated by the organisers when running the simulator using the rest of estimations as input.
When submitting the results of the CCM public test set to the organisers, teams must provide information about
the modalities used,
the tasks solved,
the complexity of the models (i.e., model storage in MB, number of trainable parameters, network architecture specifications in terms of number of convolutional layers, etc.),
specifications of the used hardware (e.g., operating system, kernel version, GPU, GPU Memory [GB], CPU, CPU cores, memory [GB], storage [GB], consumption [W]), and
the contribution of each member (research groups).
Ranking
The overall ranking is based on the aggregation (average) of the performance scores.
The organisers will use results from the random case to calculate the estimation of the filling mass and the object mass if one (or more) of the tasks is (are) not submitted by a team. The final score resulting from the set of 10 performance scores will be weighed based on the number of tasks submitted.
Only submissions which include the source code for the evaluation on the private CCM test set will valid for the ranking. Source codes that are not reproducible will get a 0 score.
The organisers will provide rankings for individual tasks and groups of tasks, such as (i) filling type and level; (ii) container capacity and dimensions; and (iii) filling mass.
Starting kit and documentation
Evaluation toolkit + script to pre-process the dataset
[code]
Vision baseline for CORSMAL Benchmark: a vision-based algorithm, part of a larger system, proposed for localising, tracking and estimating the dimensions of a container with a stereo camera.
[paper][code][webpage]
LoDE: a method that jointly localises container-like objects and estimates their dimensions with a generative 3D sampling model and a multi-view 3D-2D iterative shape fitting, using two wide-baseline, calibrated RGB cameras.
[paper][code][webpage]
Mask R-CNN + ResNet-18: Vision baseline for filling properties estimation. Independent classification of filling level and filling type using a re-trained ResNet-18 and a single RGB image crop extracted from the most confident instance estimated by Mask R-CNN in the last frame of a video. The baseline works only with glasses and cups, and fails with non-transparent containers (extra class opaque). We refer to this baseline as Mask R-CNN+RN18 in the leadeboard (run for each camera view independently).
Real-to-simulation framework: the framework complements the CORSMAL Containers Manipulation dataset with a human-to-robot handover with a simulated robot arm in a simulation environment, while estimations of the physical properties of a manipulated container are estimated by a perception algorithm using real-world audio-visual recordings from the dataset.
The simulated robot arm is controlled to receive the container from the human by using the estimations of a perception algorithm (e.g., the solutions developed by the teams) and provides the applied forces in the moment of the simulated handover. The framework enables the visualisation and assessment of the audio-visual solutions developed by the teams in terms of safeness and accuracy for human-to-robot handovers.
[paper][code][webpage]
Vision baseline for the real-to-simulation framework: a vision-based algorithm that improves the vision baseline for CORSMAL Benchmark, including filling level and type classification over time from the estimated object masks, and integrating an improved version of LoDE for estimating the container dimensions.
Baselines for the audio-based classification of the content in a container: 12 uni-modal baselines that use only audio as input data to solve the joint classification of filling level and filling type. The baselines compute different types of features, such as spectrograms, Zero-Crossing Rate (ZRC), Mel-Frequency Cepustrum Coefficients (MFCC), chromagram, mel-scaled spectrogram, spectral contrast, and tonal centroid features (tonnetz), and provide the features as input to three classifiers, namely k-Nearest Neighbour (kNN), Support Vectot Machine (SVM), and Random Forest (RF).
[arxiv]
[code]
Along with the framework, we provide
Offline reconstructed containers as 3D meshes and point clouds. The reconstructed containers are used only in the simulator to render the object and visualise the human-to-robot handover as close as possible to the reality. We provide to the participants the 3D meshes and point clouds only for the training set. Reconstructed containers
Annotations of the handover starting frame. These annotations enable the robot to approach the container and perform the handover in simulation. Annotations for the training set will be provided to the participants soon.
Annotations of the container trajectory. These annotations enable the visualisation in simulation of the trajectory executed by the container before the robot approaches the container for the the handover. These annotations are provided in the form of poses (location and orientation of the object) in 3D over time. These annotation for the training set will be provided to the participants soon.