![]()
CORSMAL Challenge: Multi-modal fusion and learning for robotics
The ongoing challenge has been updated with additional tasks and performance scores.
Click here for more info and results.
Description
A major challenge for human-robot cooperation in household chores is enabling robots to predict the properties of previously unseen containers with different fillings. Examples of containers are cups, glasses, mugs, bottles and food boxes, whose varying physical properties such as material, stiffness, texture, transparency, and shape must be inferred on-the-fly prior to a pick-up or a handover.
The challenge focuses on the estimation of the capacity and mass of containers, as well as the type, mass and percentage of the content, if any. Participants will determine these physical properties of a container while it is manipulated by a human. Containers vary in their physical properties (shape, material, texture, transparency, and deformability). Containers and fillings are not known to the robot: the only prior information available is a set of object categories (glasses, cups, food boxes) and a set of filling types (water, pasta, rice). Previous and related challenges/benchmarks, such as the Amazon Picking Challenge or the Yale-CMU-Berkeley (YCB) benchmark, focus on tasks where robots interact with objects on a table and without the presence of a human, for example grasping objects, table setting, stacking cups, or assembling/disassembling objects.
Advancements in this research field will help the integration of smart robots into people's lives to perform daily activities involving objects and handovers. For example, this is a step towards supporting people with disabilities in performing everyday activities.
The CORSMAL Containers Manipulation dataset
CORSMAL distributes an audio-visual-inertial dataset of people interacting with containers, for example while pouring a filling into a glass or shaking a food box. The dataset is collected with four multi-sensor devices (one on a robotic arm, one on the human chest and two third-person views) and a circular microphone array. Each device is equipped with an RGB camera, a stereo infrared camera and an inertial measurement unit. In addition to RGB and infrared images, each device provides synchronised depth images that are spatially aligned with the RGB images. All signals are synchronised, and the calibration information for all devices, as well as the inertial measurements of the body-worn device, is also provided.
| Camera 1 | Camera 2 | Camera 3 | Camera 4 | Audio |
 |
 |
 |
 |
The dataset consists of 1140 audio-visual-inertial recordings of people interacting with (15) containers, using 4 cameras (RGB, depth, and infrared) and a 8-element circular microphone array. Containers are either empty (0%) or filled at 2 different levels (50%, 90%) with 3 different types of content (water, pasta, rice). For example, people can pour a liquid in a glass/cup or shake a food box.
The dataset is split into training set (9 containers), public testing set (3 containers), and private testing set (3 containers). We provide to the participants with the annotations of the capacity of the container, filling type, filling level, the mass of the container, and the mass of the filling for the training set. No annotations will be provided for public testing set while private testing set will not be released to the participants. The containers for each set are evenly distributed among the three container types.
The CORSMAL Challenge includes three scenarios with an increasing level of difficulty, caused by occlusions or subject motions:
 Scenario 1. The subject sits in front of the robot, while a container is on a table. The subject pours the filling into the container, while trying not to touch the container, or shakes an already filled food box, and then initiates the handover of the container to the robot.
Scenario 1. The subject sits in front of the robot, while a container is on a table. The subject pours the filling into the container, while trying not to touch the container, or shakes an already filled food box, and then initiates the handover of the container to the robot.
 Scenario 2.
The subject sits in front of the robot, while holding a container. The subject pours the filling from a jar into a glass/cup or shakes an already filled food box, and then initiates the handover of the container to the robot.
Scenario 2.
The subject sits in front of the robot, while holding a container. The subject pours the filling from a jar into a glass/cup or shakes an already filled food box, and then initiates the handover of the container to the robot.
 Scenario 3.
A container is held by the subject while standing to the side of the robot, potentially visible from one third-person view camera only. The subject pours the filling from a jar into a glass/cup or shakes an already filled food box, takes a few steps to reach the front of the robot and then initiates the handover of the container to the robot.
Scenario 3.
A container is held by the subject while standing to the side of the robot, potentially visible from one third-person view camera only. The subject pours the filling from a jar into a glass/cup or shakes an already filled food box, takes a few steps to reach the front of the robot and then initiates the handover of the container to the robot.
Webpage to access and download the dataset.
Note that participants will receive the password to access the public testing set after completing the registration form and sending the request to the organisers.
Tasks
Prior to a human-to-robot handover, the robot must determine on-the-fly the weight of a container (e.g. the amount and type of content). This estimation will enable the robot to apply the correct force when grasping it, avoiding slippage, crashing the container or spilling its content.
We define the weight of the object handled by the human as the sum of the mass of an unseen container and the mass of the unknown filling within the container. However, we focus the challenge only towards the estimation of the mass of the filling (overall task). To estimate the mass of the filling, we expect a perception system to reason on the capacity of the container and to determine the type and amount of filling present in the container.
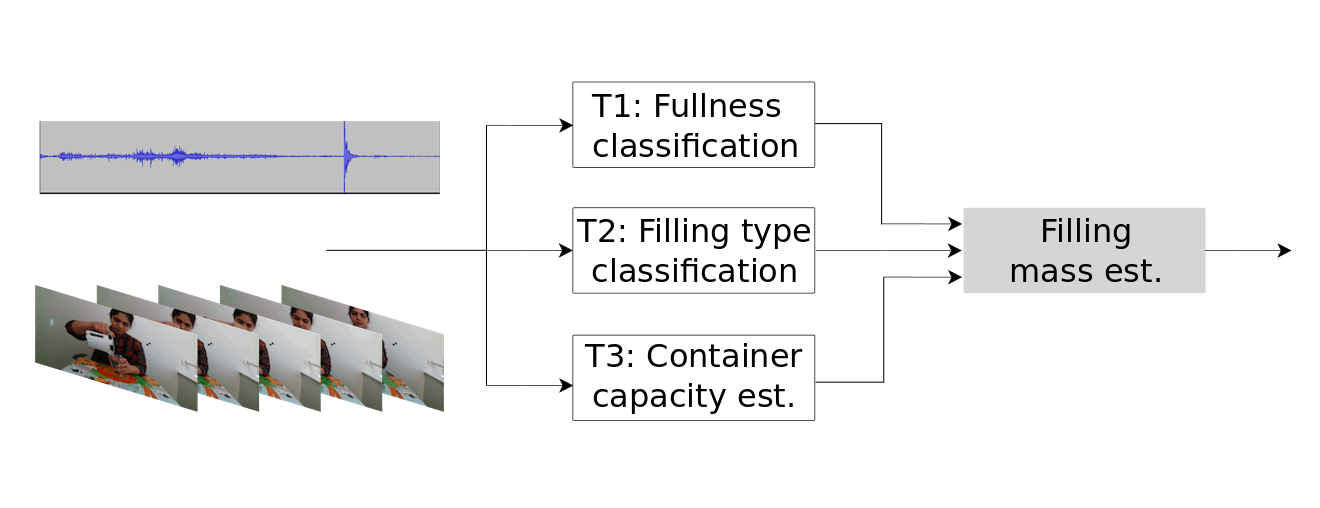
Therefore, we identify three tasks for the participants:
For each recording related to a container, we then compute the filling mass estimation using the estimations of filling level from T1, filling type from T2, and container capacity from T3, and using the prior density of each filling type per container. The density of pasta and rice is computed from the annotation of the filling mass, capacity of the container, and filling level for each container. Density of the water is 1 g/mL. The formula selects the annotated density for a container based on the estimated filling type.
Starting kit and documentation
Evaluation toolkit + script to pre-process the dataset
[code]
Vision baseline for CORSMAL Benchmark: a vision-based algorithm, part of a larger system, proposed for localising, tracking and estimating the dimensions of a container with a stereo camera.
[paper][code][webpage]
LoDE: a method that jointly localises container-like objects and estimates their dimensions with a generative 3D sampling model and a multi-view 3D-2D iterative shape fitting, using two wide-baseline, calibrated RGB cameras.
[paper][code][webpage]
Mask R-CNN
[paper][code]
SiamMask
[paper][code]
ResNet-18 (network available in PyTorch)
[paper][code]
Mask R-CNN + ResNet-18: Vision baseline for filling properties estimation. Independent classification of filling level and filling type using a re-trained ResNet-18 and a single RGB image crop extracted from the most confident instance estimated by Mask R-CNN in the last frame of a video. The baseline works only with glasses and cups, and fails with non-transparent containers (extra class opaque). We refer to this baseline as Mask R-CNN+RN18 in the leadeboard (run for each camera view independently).
[code] (COMING SOON)
Additional references
[document]
Evaluation
Performance scores
For filling level classification (Task 1) and filling type classification (Task 2), the organisers compute the Weighted Average F1-score (WAFS) across the classes, each weighted by the number of recordings in each class. For container capacity estimation (Task 3), the organisers compute the relative absolute error between the estimated and the annotated capacity for each configuration, and then compute the Average Capacity Score (ACS), that is the average score across all the configurations. The score for each configuration is computed as the exponential of the negative relative absolute error. For filling mass estimation, the organisers compute the relative absolute error between the estimated and the annotated filling mass for each configuration, unless the annotated mass is zero (i.e. empty) and then the estimation is set to zero if the estimation is also zero, otherwise equal to the estimation. The organisers then compute the Average filling Mass Score (AMS), that is the average score across all the configurations, as done for the container capacity estimation. If the capacity of the container or the filling mass in one configuration is not estimated (value should be -1), then the score is set to zero.
Note: The final score (AMS) will be weighed based on the number of tasks submitted (i.e. 0.33 for one task, 0.66 for two tasks, 1 for the three tasks).
See the document for technical details on the performance measures.
Submission guidelines
Participants must submit the estimations for each configuration of the public testing set in a csv file to corsmal-challenge@qmul.ac.uk. Each row corresponds to the respective configuration (as object id and sequence id), the third column is the estimated filling level class (0, 50 or 90), the fourth column is the estimated filling type class (0: empty, 1: pasta, 2: rice, 3: water), and the fifth column is the estimated capacity of the container in millilitres. Participants can compete to any or a combination of the 3 tasks. Columns related to tasks not addressed by the participants should be filled with -1 values. Method failures or configurations not addressed should also be filled with -1 values.
Participants should also include in the body of the email:
- Team name
- Modalities employed (RGB, IR, Depth, Audio, IMU)
- Number of (1, 2, 3, 4) and which views participants employed (demonstrator, manipulator, left side-view, right side-view)
- Completed task(s) (T1, T2, T3)
- Execution time in seconds for the complete execution of the public test.
Participants will submit the source code and executable files that will be run by the organisers on the private test set to generate the estimations of the same properties for each configuration. The source code should be properly commented and easy-to-run. For achieving so, participants should provide an environment (e.g. docker or conda) that can locally install all the necessary libraries to reproduce and run the code. The organisers will require to input an absolute path to the testing set to perform the evaluation. Therefore, participants should prepare the source code in such a way that data path is provided as input argument. Also, we recommend participants to have a single README file with a brief description; employed hardware, programming language, and libraries; installation instructions; demo test; running instructions on the testing set; external links to pre-trained models to download, if any; and licence.
Note that organisers will run the submitted software with the following specifications:
Hardware
- CentOS Linux release 7.7.1908 (server machine)
- Kernel: 3.10.0-1062.el7.x86_64
- GPU: (4) GeForce GTX 1080 Ti
- GPU RAM: 48 GB
- CPU: (2) Xeon(R) Silver 4112 @ 2.60GHz
- RAM: 64 GB
- Cores: 24
Libraries
- Anaconda 3 (conda 4.7.12)
- CUDA 7-10.2
- Miniconda 4.7.12
The source code will be deleted by the organisers after the release of the results.
Rules
Any individual or research group can download the dataset and participate in the challenge. The only prior knowledge available to the models is the filling types (water, rice, and pasta), the filling levels (empty, 50%, and 90%), and the high-level category of the containers (cup, glass, food box). The organisers do not allow the use of prior 3D object models. Inferences must be generated automatically by a model that uses as input any of the provided data modalities or a combination (for example, video, audio or audio-visual fusion); i.e., non-automatic manipulation of the testing data (e.g., manual selection of frames) is not allowed. The use of additional training data is allowed but the provided testing set cannot be used for training. Models must perform the estimations for each testing sequence only using data from that sequence, and the training set; but not from other sequences. Learning (e.g. model fine tuning) across testing sequences is not allowed.
Leaderboard
The evaluation is based on the results of both testing sets and participants will be ranked across all configurations. To calculate the estimation of the filling mass (overall task), the organisers use results from the random case if one (or two) of the tasks is (are) not submitted by a participant team.
Note: The score for the overall task is not a linear combination of the scores outputted for Task 1, Task 2, and Task 3, but it takes into consideration the formula for computing the filling mass based on the estimations of each task for each configuration. This means that a method with lower Task 1, Task 2 and Task 3 scores can obtain a higher Overall score compared to other methods because the performance on each run is more accurate in general.
More details in the technical document.
The organisers will declare the winner of the challenge based on the score on the overall task. The best-performing entries will be presented at the conference venue. Selected participants will be invited to co-author a paper to discuss and analyse the research outcomes of the challenge.
Overall task: Filling mass estimation
Task 1: Filling level classification
Task 2: Filling type classification
Task 3: Container capacity estimation
Legend:
- View 1: view from the fixed camera on the left side of the manipulator
- View 2: view from the fixed camera on the right side of the manipulator
- View 3: view from the fixed camera mounted on the manipulator (robot)
- View 4: view from the moving camera worn by the demonstrator (human)
- A: audio modality
- RGB: colour data
- D: depth data
- IR: infrared data from narrow-baseline stereo camera
- ZCR: Zero-crossing rate
- MFCC: Mel-frequency cepstrum coefficients
- ZCR: Zero-crossing rate
- A5F: Audio 5 features (MFCC, chromogram, mel-scaled spectrogram, spectral contrast, tonal centroid)
- kNN: k-Nearest Neighbour classifier
- SVM: Support Vector Machine classifier
- RF: Random Forest classifier
- PCA: Principal component analysis
Organisers
Alessio Xompero, Queen Mary University of London (UK)
Andrea Cavallaro, Queen Mary University of London (UK)
Apostolos Modas, École polytechnique fédérale de Lausanne (Switzerland)
Aude Billard, École polytechnique fédérale de Lausanne (Switzerland)
Dounia Kitouni, Sorbonne Université (France)
Kaspar Althoefer, Queen Mary University of London (UK)
Konstantinos Chatzilygeroudis, University of Patras (Greece)
Nuno Ferreira Duarte, École polytechnique fédérale de Lausanne (Switzerland)
Pascal Frossard, École polytechnique fédérale de Lausanne (Switzerland)
Ricardo Sanchez-Matilla, Queen Mary University of London (UK)
Riccardo Mazzon, Queen Mary University of London (UK)
Véronique Perdereau, Sorbonne Université (France)
Sponsors
![]()
![]()
![]()
![]()
Partners
![]()
![]()
![]()









