![]()
The 2020 CORSMAL Challenge
Multi-modal fusion and learning for robotics
![]()
![]()

Program (15 Jan 2021, starts at 3pm CET)
| 3:00 pm CET Welcome and opening |
|||||||||||
| 3:05 pm CET Collaborative Object Recognition, Shared Manipulation and Learning Andrea Cavallaro Queen Mary University of London & Alan Turing Institute |
|||||||||||
| 3:20 pm CET The CORSMAL Challenge Alessio Xompero Queen Mary University of London |
|||||||||||
| 3:35 pm CET Top-1 CORSMAL Challenge 2020 submission: Filling mass estimation using multi-modal observations of human-robot handovers [paper] [video] [slides] [arxiv] [code] Because It's Tactile team (Tampere University, Finland; Queen Mary University of London, U.K.)
|
|||||||||||
| 3:45 pm CET Audio-Visual Hybrid Approach for Filling Mass Estimation [paper] [video] [slides] [code] HVRL team (Keio University, Japan)
|
|||||||||||
| 3:55 pm CET VA2Mass: Towards the Fluid Filling Mass Estimation via Integration of Vision & Audio [paper] [video] [slides] Concatenation team (City University of Hong Kong)
|
|||||||||||
| 4:05 pm CET Round-table |
|||||||||||
| 4:35 pm CET Challenge leaderboard and next steps |
|||||||||||
Leaderboard
Overall task: Filling mass estimation
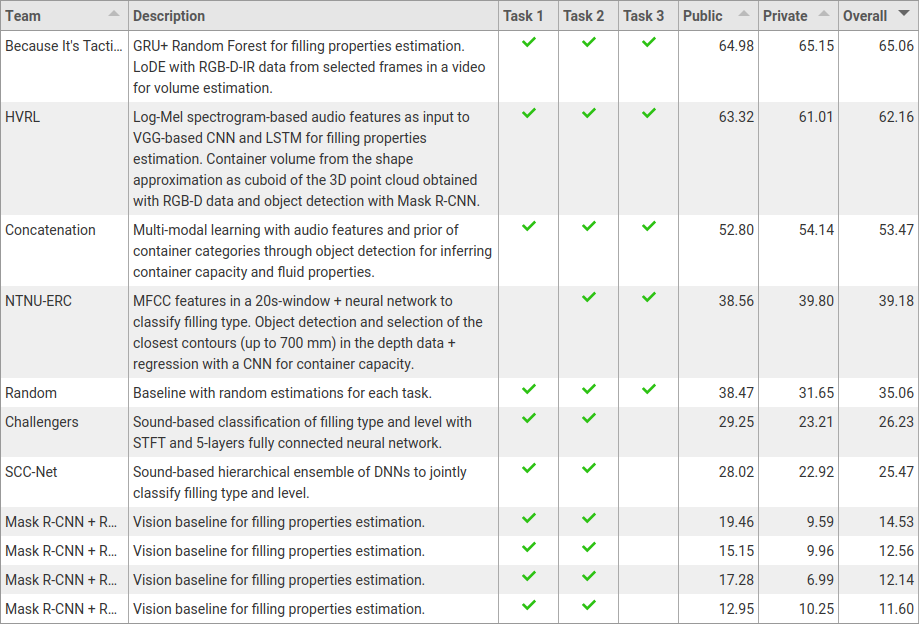
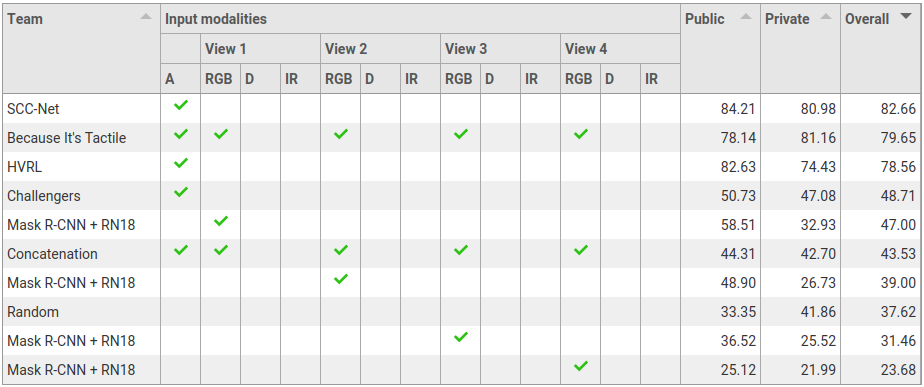
Task 1: Filling level classification
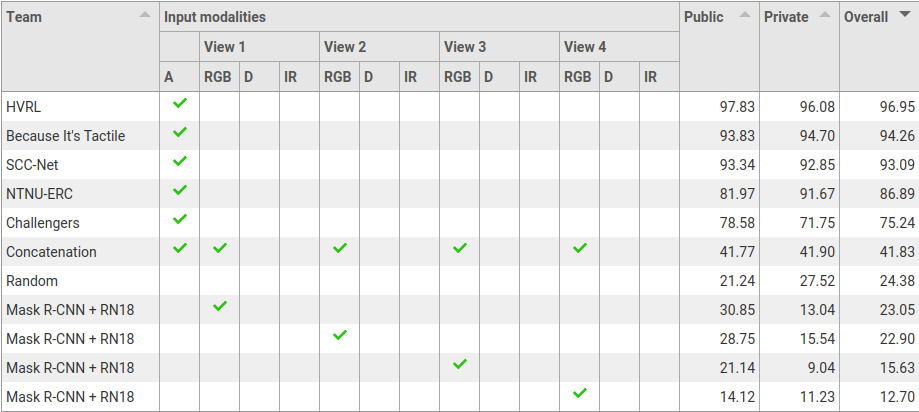
Task 2: Filling type classification
Task 3: Container capacity estimation
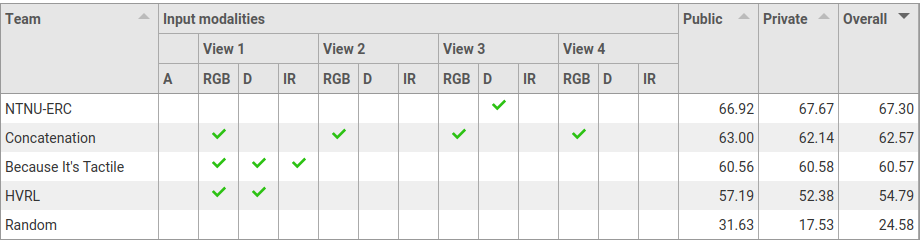
Legend:
- View 1: view from the fixed camera on the left side of the manipulator
- View 2: view from the fixed camera on the right side of the manipulator
- View 3: view from the fixed camera mounted on the manipulator (robot)
- View 4: view from the moving camera worn by the demonstrator (human)
- A: audio modality
- RGB: colour data
- D: depth data
- IR: infrared data from narrow-baseline stereo camera
Organisers
Alessio Xompero, Queen Mary University of London (UK)
Andrea Cavallaro, Queen Mary University of London (UK)
Apostolos Modas, École polytechnique fédérale de Lausanne (Switzerland)
Aude Billard, École polytechnique fédérale de Lausanne (Switzerland)
Dounia Kitouni, Sorbonne Université (France)
Kaspar Althoefer, Queen Mary University of London (UK)
Konstantinos Chatzilygeroudis, University of Patras (Greece)
Nuno Ferreira Duarte, École polytechnique fédérale de Lausanne (Switzerland)
Pascal Frossard, École polytechnique fédérale de Lausanne (Switzerland)
Ricardo Sanchez-Matilla, Queen Mary University of London (UK)
Riccardo Mazzon, Queen Mary University of London (UK)
Véronique Perdereau, Sorbonne Université (France)
Sponsors
![]()
![]()
![]()
![]()
Partners
![]()
![]()
![]()









